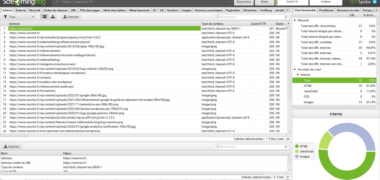
Le fait que Google et les autres moteurs de recherche puissent parcourir votre site convenablement votre site est la base du référencement naturel : c’est ce qu’on appelle le crawl. Si ensuite vos contenus sont jugés « pertinents » et bien conçu, Google les ajoutera et les affichera dans les résultats lors des recherches des internautes : c’est ce qu’on appelle l’indexation.
Cela tombe bien, on parle de ces deux sujets dans cette section du mixeur afin de vous aider à faire comprendre vos contenus au moteur de recherche.
Notre dernier article dans la section Optimisation technique SEO
Le fichier llms.txt est-il vraiment utilisé par les IA ? Peut-il améliorer votre GEO dans tous les LLM ? Notre test sur 60 jours et 33 000 passages de robots…
Un plan de redirection bien conçu est impératif pour réussir une refonte ou migration de site sans perdre de trafic ni nuire au SEO. On vous explique en détails comment…
Isolées de votre maillage interne, les pages orphelines pénalisent votre SEO. Découvrez comment les identifier et les corriger grâce à nos bonnes pratiques
Le classement dans les résultats de recherche Google est essentiel pour garantir une bonne visibilité et attirer un trafic qualifié sur votre site. La première étape pour y parvenir est…
Toute prestation SEO complète nécessite un audit SEO et notamment un audit technique. Dans cet article, vous allez découvrir les étapes à suivre pour auditer la santé technique de votre…
Comment indexer ou désindexer une URL ? Comment bloquer le crawl ? Comment empêcher Google de crawler une URL ? Découvrez le tout dernier guide des mixeurs de SeoMix !
Découvrez tout ce qu'il faut savoir en référencement local, le SEO spécialisé dans la visibilité de proximité ! Pourquoi développer son référencement local ? Quels sont les critères de classement,…
Découvrez ce qu'est une page 404 et nos préconisations pour les corriger rapidement (redirection 301, personnalisation de page d'erreur ou encore code 410) ! Vous limiterez la perte de trafic…
6 bonnes pratiques pour indexer correctement et efficacement tout type de site Internet : l'arborescence, le maillage interne, le sitemap et bien plus.
Pourquoi et comment mettre en place un fichier robots.txt pour le CMS WordPress ? Découvrez le guide d'optimisation complet pour votre référencement naturel ainsi qu'un modèle tout prêt à être…
Geoffrey Crofte nous dévoile les secrets des microformats et microdata pour le CMS WordPress, avec de nombreux codes et plugins pour les intégrer proprement.
Pourquoi le bouton ajouter au panier peut nuire au référencement naturel d'un site ecommerce, et comment contourner cette problématique sur votre boutique en ligne ?
En collaboration avec Johan Bleuzen, SeoMix teste le référencement naturel de contenus en Ajax. Le verdict est sans appel : impossible à référencer sans configurer de manière optimale son serveur.
Google prend en compte les sitemaps image. Mais quel impact ce fichier possède t-il sur le référencement naturel des images ? Aucun d'après le test réalisé par SeoMix...
Depuis quelques temps déjà, Google personnalise ses résultats en fonction de votre historique de navigation. Voici deux méthodes pour s'en débarrasser.
A quelle vitesse Google indexe t-il votre sitemap ? Il le fait selon la fréquence de mise à jour de votre fichier xml. Optimisez donc dès maintenant le crawl de…
Vous aimerez ces autres thématiques sur "Référencement naturel"