Aujourd'hui encore, trop de gens méconnaissent ou mélangent des concepts clés du référencement naturel, et notamment tout ce qui concerne le crawl et l'indexation des URL de votre site. Cela concerne vos contenus classiques, mais aussi n'importe quelle ressource : PDF, images, CSS, polices d'écriture, etc.
C'est pourtant un point clé (ou bloquant) pour améliorer votre visibilité ! En SEO, il est impératif de maîtriser ces éléments pour donner plus de poids et de visibilité à vos contenus pertinents, tout en supprimant les URL inutiles de Google.
Définitions
Reprenons à zéro avec quelques définitions :
Que signifie crawler ?
Crawler, c'est le fait, pour un moteur de recherche, de parcourir l'ensemble des contenus d'un site, c'est à dire l'ensemble de ses URL : ses contenus HTML, ses images, ses vidéos, ses fichiers JavaScript et ainsi de suite. Sans crawl, Google ne peut pas découvrir un contenu, et ce dernier ne peut donc pas apparaître lors d'une recherche sur le moteur.
Pour être crawlée, une URL doit entrer dans l'un de ces cas de figure :
- Un lien permet d'y accéder (et Google a trouvé ce lien) ;
- Un fichier sitemap XML liste cette URL (et ce sitemap a été crawlé par Google ou a été soumis au moteur de recherche dans votre compte Search Console) ;
- Un ping (une "notification") est envoyée au moteur de recherche concernant cette URL ;
- Le moteur de recherche a trouvé cette URL via un autre moyen (par exemple via des outils de tests en ligne ou d'autres données utilisateur).
Que signifie indexer ?
Indexer, c'est le fait d'analyser et d'ajouter dans une base de données une URL précise.
L'indexation est l'étape qui suit le crawl. Une fois que le moteur de recherche a parcouru une URL, il va analyser son contenu puis il l'ajoutera à sa base de données (son index). Il pourra ainsi le proposer aux internautes lors de leurs recherches.
Lors de l'indexation, Google va essayer de comprendre le mieux possible le contenu. Sans indexation, il est impossible d'apparaître dans les résultats des moteurs de recherche.
Comment fonctionnent le crawl et l'indexation de Google ?
Google, comme la plupart des moteurs de recherche, dédie des ressources importantes pour pouvoir crawler un maximum d'URL et pour pouvoir ensuite les indexer. A l'échelle mondiale, cela représente un volume gigantesque de données.
Dans un monde parfait, vous devez faire indexer uniquement les URL pertinentes et éliminer tout le reste. Cela aidera d'ailleurs à mieux transmettre la popularité entre vos pages. En effet, chaque lien transmet de la popularité à l'URL ciblée. Voyez cela comme le bouche à oreille : plus on parle de vous, plus vous êtes connu. En référencement naturel, c'est pareil : plus j'ai de liens (internes comme externes), plus la page est populaire et "puissante".
Avant d'agir, il faut donc comprendre quelques éléments :
Comprendre ce que Google Indexe
Nous parlerons plus loin de la meilleure façon de choisir un "bon contenu", mais il faut avant tout comprendre ce que Google doit crawler et indexer. On ne parle en effet pas uniquement de vos vraies publications (vos pages, vos articles, etc.). Google va en réalité crawler tout ce qu'il trouvera sur une page : le contenu HTML, les fichiers CSS (la "mise en page"), les images, les polices d'écritures, les images, etc.
En aucun cas vous ne devez bloquer le crawl et l'indexation de ces éléments supplémentaires, puisqu'ils permettront à Google de juger la qualité de votre contenu, notamment en ce qui concerne la compatibilité mobile ou encore le temps de chargement. On aura donc tendance à éviter de bloquer un trop grand nombre de dossiers et d'URL dans le fichier robots.txt.
Un crawl et une indexation en deux étapes
Gardez aussi en tête que le crawl et l'indexation ne se font jamais en temps réel. En règle générale, les robots de Google le font en plusieurs étapes :
- Phase 1 :
- Google découvre une URL (ou alors l'utilisateur en soumet une) ;
- Il l'ajoute à sa liste d'attente d'URL à crawler ;
- Il crawle l'URL et indexe le contenu texte.
- Phase 2 :
- Il va ensuite ajouter cette URL dans une liste d'attente pour en générer le rendu réel (donc avec les fichiers CSS, JavaScript les images, etc.) ;
- Il génère le rendu ;
- Il ré-indexe le contenu final.
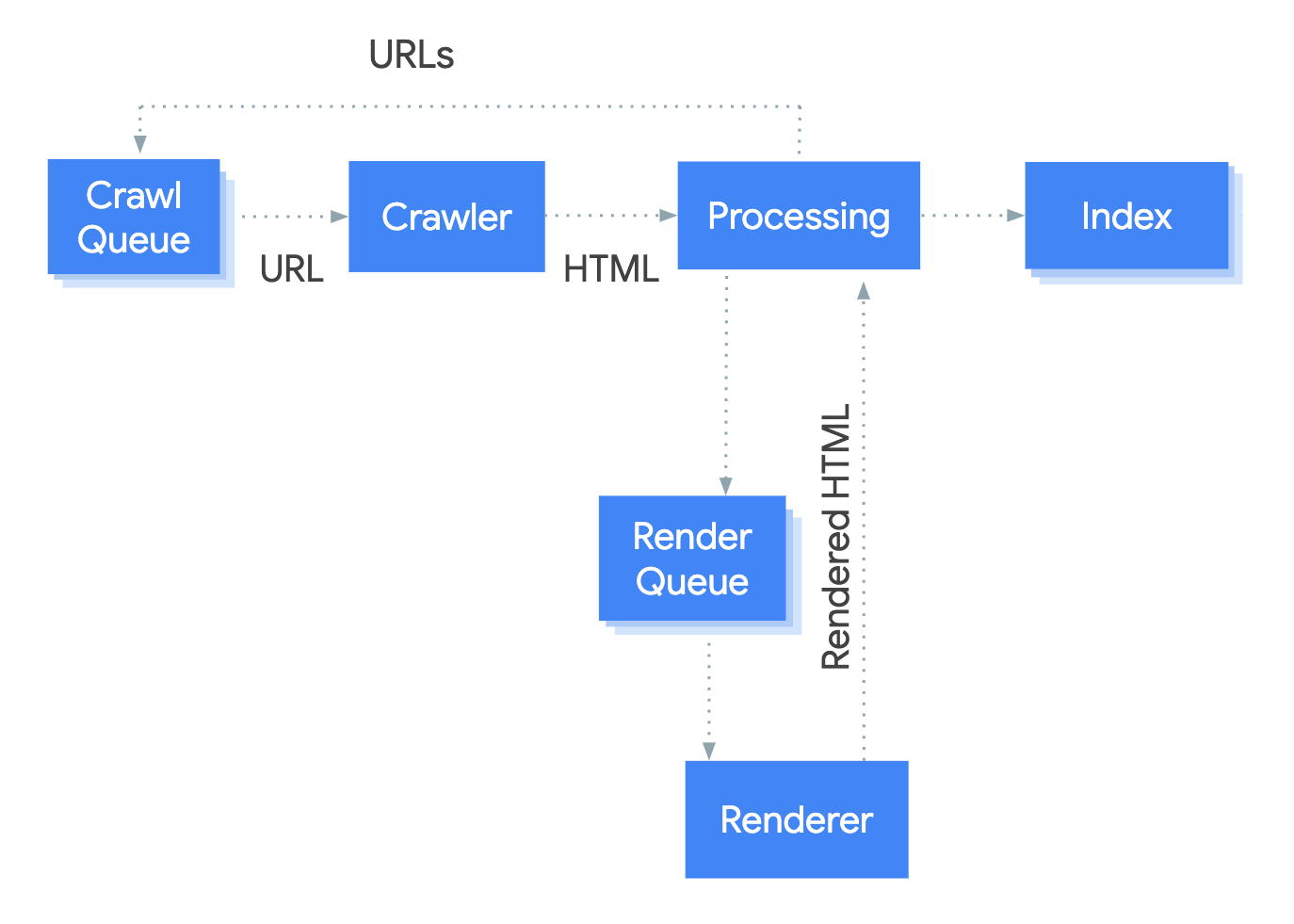
En d'autres termes, il va crawler en priorité les contenus textes, et dans un second temps toutes les ressources associées.
Le budget de crawl
Autre élément à connaître, le "budget de crawl". Google et les autres moteurs de recherche n'ont pas des ressources illimitées, et ils indexent déjà des milliards d'URL. Ils ne vont donc pas passer un temps infini sur votre site. En règle générale, ce "temps" consacré à vos contenus (ce fameux "budget") est proportionnel à la popularité du site concerné.
Le principe de base est donc simple : sur son site, on doit faire crawler et indexer uniquement les URL pertinentes pour optimiser l'utilisation de ce budget de crawl.
Rassurez-vous cependant sur cet aspect, c'est rarement une problématique SEO ayant un impact fort, sauf dans certains cas de figure où votre site aurait une popularité faible avec de très (trop) nombreuses URL, par exemple avec une navigation à facettes mal mise en place (nous en reparlerons plus loin).
Noindex : tout le reste n'existe plus
Dernier élément à savoir : la directive noindex ou un blocage par le fichier robots.txt bloqueront toute tentative de Google d'analyser le contenu de la page. A partir du moment où vous dites au moteur de recherche de ne pas indexer une URL ou d'en bloquer l'accès, toutes les informations de la page ne seront plus prises en compte.
Si vous rajoutez, modifiez ou supprimez d'autres éléments, Google va purement et simplement les ignorer. Ce sera notamment le cas pour :
- La balise Title ;
- la balise méta description ;
- Les autres directives incluses dans la balise robots ;
- La balise canonical ;
- Des éventuelles meta refresh ;
- Le balisage Schema.org ;
- Etc.
Les problématiques courantes
Les besoins réguliers sur l'indexation et le crawl
La raison pour laquelle on aborde ce sujet est qu'il existe des problématiques récurrentes en référencement naturel concernant ces deux aspects. Ainsi, il est indispensable, pour la personne en charge du référencement naturel d'un site, de savoir effectuer les actions suivantes :
- indexer une URL précise, ce qui est théoriquement natif (sauf problème technique) ;
- désindexer un contenu ;
- bloquer toute future indexation ;
- bloquer le crawl.
Très souvent, on découvre lors de nos audits SEO des sites qui indexent des URL inutiles (contenus dupliqués, trop courts, etc.), et à l'inverse qui bloquent des URL pertinentes, ou des URL qui auraient permis d'obtenir de la popularité.
Que dois-je indexer, et pourquoi est-ce important ?
Avant d'entrer dans le détail des méthodologies, encore faut-il savoir quand agir. Bien souvent, des utilisateurs oublient de bloquer l'indexation ou de désindexer certains éléments. Et à l'inverse, d'autres ne parviennent pas à faire ajouter leurs contenus dans l'index de Google. La première question à se poser est :
Est-ce que cette URL est pertinente ?
De cette réponse dépendra une grande partie de vos actions. Et il faut bien comprendre la notion de pertinence. Elle inclut en réalité plusieurs éléments :
- Le contenu répond à un besoin utilisateur ;
- Ce besoin est régulièrement recherché par les internautes sur les moteurs de recherche (voir le volume de recherche de votre mot clé) ;
- Dans l'idéal :
- votre contenu est meilleur ou se différencie de ce que font vos concurrents ;
- vous pouvez répondre au besoin utilisateur grâce à vos produits et services ;
- Ce contenu est unique (vous n'avez pas fait de copier/coller) ;
- Il n'est pas redondant avec une autre page de votre site, et il ne cible pas non plus un besoin auquel une autre publication répond déjà parfaitement.
Ensuite, si jamais l'URL concernée ne rentrait pas dans ces cas de figure, il existe deux autres raisons qui doivent vous pousser à conserver cette URL (tout du moins à ne pas la désindexer) :
- c'est une ressource utilisée dans l'affichage de la page (image, CSS, etc.)
- c'est une URL "populaire". Si un contenu de votre site Internet reçoit des liens depuis d'autres sites, vous ne devrez jamais le désindexer. Par contre, vous pouvez sans soucis faire une redirection 301 si l'URL n'est plus pertinente, car cela permet de retirer un contenu sans en perdre la popularité (là encore nous en reparlerons plus loin).
Nous allons maintenant passer en revue les différentes actions récurrentes que l'on doit mener, en référencement naturel, pour tout ce qui concerne l'action des moteurs de recherche.
Bloquer le crawl
Éviter le crawl de l'URL
Quand on souhaite désindexer une URL, ne jamais l'indexer ou encore en bloquer le crawl, vous devrez d'abord empêcher Google de découvrir à nouveau cette URL précise. Ce sera par exemple le cas quand vous voulez bloquer l'accès à un élément "privé" ou pour éviter de lui faire perdre du temps de crawl et d'indexation (contenu pauvre, dupliqué ou qui ne cible aucun mot clé). L'idée est de travailler en amont et de faire en sorte que Google ne trouve, ou ne retrouve, jamais ce contenu.
Pour faire cela, il n'existe pas d'autre solution que de vous assurer que le moteur de recherche ne puisse pas découvrir cette URL. Cela implique donc les éléments suivants :
- Aucun lien n'existe vers cette URL (que ce soit sur votre site ou sur d'autres) ;
- Le contenu n'est présent dans aucun fichier sitemap ;
- Aucun ping ou notification n'est généré (pings classiques de WordPress, API, etc.) ;
- Vous ne soumettez pas cette URL dans des outils en ligne comme :
- les outils de Google (Search Console, test mobile, test AMP, test schema.org, etc.) ;
- d'autres outils externes qui pourraient lister ces URL (outils de test de vitesse, de sécurité, d'accessibilité, etc.).
Pour bloquer le crawl, c'est de loin la meilleure solution : si Google ne trouve pas un contenu, impossible pour lui de le parcourir et de l'indexer.
Bloquer l'accès et donc le crawl
Ensuite, que faire si vous souhaitez empêcher Google de crawler une URL précise mais que vous ne pouvez empêcher Google de connaître cette dernière ? En d'autres termes, vous êtes dans l'un des cas de figure cités juste avant. Dans ce cas, il existe deux solutions qui permettent de bloquer le crawl (on ne parle toujours pas d'indexation ici).
Une protection Htpasswd
La meilleur méthode est le .htpasswd. Dès qu'un robot ou un internaute essaiera d'accéder à l'URL concernée, un login/mot de passe lui sera demandé. Cela bloque complètement l'accès. C'est notamment très utile pour des données potentiellement sensibles, ou encore pour des serveurs de développement.
Pour mettre cela en place, je vous invite à consulter les innombrables tutoriels sur ce sujet un peu partout sur le web.
Le fichier robots.txt
Seconde méthode efficace : vous allez spécifier dans le fichier robots.txt la ou les URL à bloquer. La plupart des moteurs de recherche prendront alors la directive en compte pour ne pas crawler les contenus concernés.
Attention cependant, cette méthode a plusieurs défauts :
- cela ne bloquera pas les internautes, mais seulement les robots des moteurs de recherche ;
- cela permet aux concurrents de voir ce que vous voulez "cacher" ;
- si le contenu était indexé avant le blocage, il le restera car le fichier robots.txt n'agit pas sur l'indexation.
Des liens en Nofollow ?
Vous pourriez être tenté de mettre un attribut nofollow aux différents liens qui pointent vers les URL à ne pas crawler. Théoriquement, cela indique aux robots de ne pas suivre ces liens, et donc de ne pas les crawler. Dans le code, cela ressemble à cela :
Exemple d'un lien en nofollow
<a href="URL" rel="nofollow">texte de mon lien</a>Malheureusement, c'est une mauvaise idée :
- Cela n'empêchera pas les moteurs de recherche de trouver ces URL par d'autres moyens ;
- Google indique depuis plusieurs mois qu'il ne considère pas la directive nofollow d'un lien comme obligatoire. Il peut donc potentiellement passer outre pour crawler quand même l'URL concernée.
Bloquez l'indexation par sécurité
Si vous êtes parvenu à appliquer les deux premières solutions (éviter de trouver l'URL et/ou en bloquer l'accès), sachez que l'on n'est jamais trop prudent. Pour de multiples raisons, vos "protections" contre le crawl pourraient sauter (fichier htaccess supprimé, un robots.txt mis à jour, un internaute qui rajoute un lien vers ce contenu, bug technique du CMS, etc.).
Chez SeoMix, on vous conseille donc de bloquer l'indexation de toutes les URL sur lesquelles vous avez empêché le crawl. Pour cela, suivez les solutions ci-dessous.
Désindexer ou bloquer l'indexation d'un contenu
Pour désindexer, ne bloquez jamais les robots
Et oui : pour pouvoir désindexer un contenu connu par les moteurs de recherche, il ne faut surtout pas en bloquer le crawl. En d'autres termes, vous ne devez pas mettre en place des règles qui empêcheraient Google de venir parcourir les URL à faire disparaître : le fichier robots.txt et les règles de protection htaccess ne doivent donc pas être utilisées tant que le contenu ciblé n'aura pas été entièrement désindexé.
Par contre, les bonnes pratiques sur l'absence de liens vers ces contenus doivent être maintenues. En effet, Google ayant connaissance des ces pages à désindexer, inutile de faire des liens vers elles, car naturellement Google va revenir dessus tôt ou tard.
Noindex : meta robots ou entête x-robots
C'est sans doute la meilleure méthode : l'ajout de la directive noindex à l'URL entière. Comme son nom l'indique, elle permet de bloquer l'indexation. Elle permet aussi sa désindexation si celle-ci était auparavant dans la base de données du moteur de recherche.
En règle générale, on utilisera la balise meta robots dans le code HTML de vos pages, dans la partie <head>. C'est ainsi invisible pour l'internaute, mais la directive sera prise en compte par Google.
Instruction noindex dans le head
La plupart des extensions SEO des CMS, comme Yoast SEO pour WordPress, permettent nativement de gérer cela avec une option lorsque l'on modifie chaque contenu.
Vous pouvez aussi envoyer cette information par les entêtes HTTP avec l'entête x-robots. Ce sera d'ailleurs le seul moyen de transmettre cette demande de désindexation pour tous contenus non HTML (images, CSS, JavaScript, PDF, etc.).
C'est quoi un entête HTTP ?
Toutes les URL auxquelles on peut accéder envoient des entêtes HTTP. Il s’agit d’informations supplémentaires envoyées avec le contenu demandé. C’est notamment dans ces derniers que l’on stockera par exemple le statut de la page (200 « tout va bien », 404 « page non trouvée ») et diverses informations techniques. Plus d’informations ici.
Et voici cela à quoi cela peut ressembler :
Exemple d'un entête HTTP
cache-control: no-cache, must-revalidate, max-age=0
content-encoding: gzip
content-type: text/html; charset=UTF-8
date: Thu, 22 Apr 2021 13:22:00 GMT
expires: Wed, 11 Jan 1984 05:00:00 GMT
server: Apache
vary: Accept-Encoding
x-frame-options: SAMEORIGIN
200 OKVous pouvez utiliser l'un ou l'autre (l'entête ou le balise robots noindex), l'utilisation des deux en même temps n'ayant pas vraiment d'utilité.
Attention par contre, si vous avez des liens qui pointent vers l'URL que vous désindexez, la popularité de ces liens sera perdue. Gardez en mémoire que chaque lien fait vers votre site vous donne du poids. Mais si la page de destination est indisponible ou non indexable, cette popularité ne sera plus transmise au reste du site.
Notre conseil est donc simple : n'utilisez la directive noindex que si vous êtes certains que l'URL concernée ne dispose d'aucun backlink. Utilisez alors des outils comme Ahrefs ou Majestic SEO pour le vérifier.
De même, pensez aussi à regarder :
- si elle reçoit du trafic ;
- si elle est positionnée ou non sur certains mots clés (SemRush pourra fortement vous aider).
Redirection 301
Autre solution : rediriger définitivement l'URL concernée vers une autre (ce qu'on appelle une redirection 301). Google va alors la retirer de son index et ira alors crawler puis indexer la nouvelle.
Attention
Si vous optez pour cette méthode, il faut bien que ce soit une redirection permanente (301). Si à l’inverse vous utilisez une redirection 302, elle sera considérée comme temporaire et donc non prise en compte par les moteurs de recherche (nous verrons plus loin comment vérifier).
La solution de la redirection 301 est particulièrement utile pour toutes les URL qui ont des backlinks, ou qui pourraient en avoir sans que vous ne le sachiez. Cela permet de ne pas perdre la popularité des pages que l'on souhaite supprimer. Gardez bien en mémoire qu'une redirection 301 transfère la popularité de la page d'origine.
En règle générale, c'est la solution à utiliser en premier pour tous les contenus textes à désindexer sur un site actif (car il est parfois difficile de déterminer si oui ou non cette URL avait obtenu de la popularité externe).
Si à l'inverse vous êtes certain que cette URL n'avait aucun backlink, alors optez plutôt pour le noindex ou pour la solution du code 410 dont nous allons parler juste après.
Entête 410
Dernière solution potentielle pour désindexer un contenu : renvoyer un entête HTTP 410. En soi, cela ne change rien visuellement à l'URL. Mais au lieu de rediriger l'utilisateur, on indique non seulement que le contenu n'existe plus (comme pour une page d'erreur), mais surtout que ce contenu n'existera plus jamais et qu'il peut donc être désindexé sans risque. Voyez donc cela comme une erreur 404 définitive.
Contrairement aux erreurs 404 sur lesquelles Google peut revenir quasiment indéfiniment (ou tout du moins pendant de longs mois), un entête HTTP 410 va accélérer fortement la désindexation de l'URL concernée.
Attention cependant, si cette dernière avait des backlinks, ces derniers seront perdus aussi (et dans ce cas une redirection 301 est nettement préférable). On utilisera ainsi souvent les codes 410 pour les fichiers et ressources (scripts, CSS, images, font, anciens fichiers de cache et ainsi de suite).
Une canonical ?
On pourrait être tenté d'utiliser une balise canonical pour désindexer une URL et pour indiquer dans le même temps celle à prendre en compte.
C'est quoi une balise canonique ?
Il s’agit d’un code indiquant l’URL réelle d’un contenu. Il permet ainsi d’éviter la duplication de contenus, par exemple lors de l’utilisation de paramètres dans l’URL.
Cela peut être ajouté dans le <head> (comme dans l'exemple ci-dessous), mais aussi avec un entête HTTP.
Exemple de balise canonique
C'est malheureusement une mauvaise idée quand il s'agit de contenus différents (par exemple si j'utilise une canonique vers B quand je veux désindexer A). Si vous ne souhaitez plus rendre une URL accessible pour les moteurs de recherche et les visiteurs, la redirection 301 est alors la meilleure solution.
Par contre, quand il s'agit de la variante d'une URL, la balise canonical est justement conçue pour cela. Ainsi, peu importe les paramètres d'URL utilisés, on indique quelle est la vraie URL. Cela évite d'indexer des contenus dupliqués, et cela transmet correctement la popularité. Ce sera notamment le cas d'un grand nombre d'URL avec paramètres, par exemple celles que l'on retrouve lors du partage sur certains réseaux sociaux :
Exemple d'une URL avec paramètres
https://www.seomix.fr/guide-optimisation-seo/?utm_source=dlvr.it&utm_medium=facebookC'est pour cette raison que la plupart des solutions SEO pour les CMS ajoutent automatiquement une balise canonique à chaque contenu. Ainsi, si des paramètres sont ajoutés, aucun risque de dupliquer ce dernier. La Search Console vous affichera d'ailleurs toutes ces informations dans le menu "Couverture > Exclues > Autre page avec balise canonique correcte".
Ce sera d'ailleurs aussi le cas sur des URL qui sont générées par l'utilisateur, par exemple lors de l'utilisation de filtres dans une catégorie (ce qu'on appelle une navigation à facettes). Dans ce cas de figure, la réponse sera plus complexe : est-ce que ce filtre apporte un contenu unique (auquel cas on peut laisser l'indexation tranquille), ou alors c'est un contenu peu pertinent, trop proche voir dupliqué, et dans ce cas la balise canonique sera utile.
Une suppression via la Search Console ?
Puisque l'on nous a déjà posé cette question dans le passé, sachez qu'il existe aussi un moyen de retirer une URL via votre compte Search Console dans le menu "Index > Suppression".
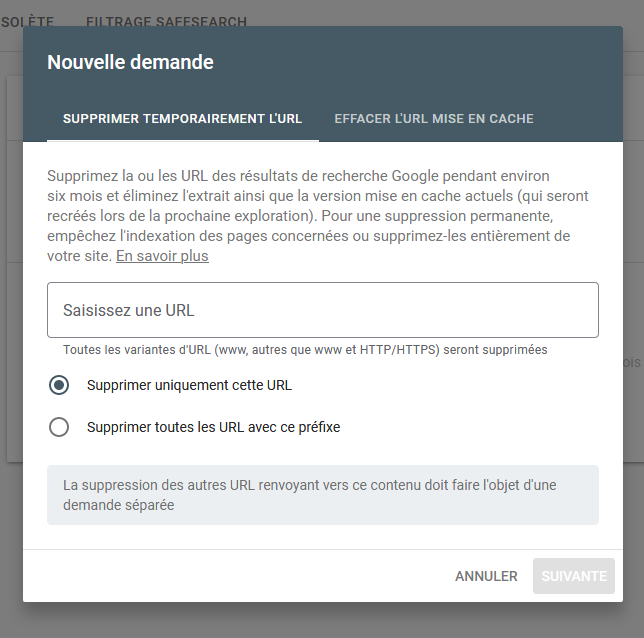
Mais ce n'est pas une vraie solution, car ce retrait ne sera que temporaire. Cela peut aider si vous avez besoin d'une action rapide, mais vous devrez impérativement utiliser l'une des solutions précédentes pour que cela soit définitif.
Besoin d'aide ?
Comme vous pouvez le voir, les notions de crawl et d'indexation font partie des aspects techniques, et peuvent être parfois complexes à mettre en place en fonction de votre site, de vos compétences ou du temps que vous avez à disposition. N'hésitez donc pas à nous contacter pour nous parler de vos problématiques.
Les mixeurs sont là
Si l'indexation et le crawl sont des problématiques sur votre site, venez nous en parler pour trouver la meilleure solution.
Comment faire ?
Méthodes et outils
Pour aller dans le cœur du sujet de manière concrète : comment faire tout cela ? Et ensuite, comment vérifier son travail ?
D'abord, pour mettre en place chaque action, voici une liste de différentes solutions non exhaustive (qui peuvent varier en fonction de votre site et du CMS éventuel que vous utilisez) :
- Les liens : Pour trouver les liens qui permettent à Google de trouver une URL, vous pouvez utiliser :
- Un logiciel de crawl (comme l'excellent Screaming Frog Spider SEO) ;
- Un outil de popularité (Majestic SEO, Ahrefs, etc.) ;
- Éventuellement le menu "Liens" de la Search Console ;
- Un outil de webanalytics avec le menu des sites référents.
- Les sitemaps :
- En règle générale, soit votre CMS le génère automatiquement, soit c'est une extension. Dans un cas comme dans l'autre, trouvez le menu de réglage pour exclure certaines URL.
- Attention, les fichiers sitemaps natifs de WordPress ne sont pas paramétrables : il faut les désactiver.
- Les pings : tout dépend de votre CMS. Dans WordPress, on peut les désactiver dans 2 menus :"Réglages > commentaires" (les trois premières options) et dans "Réglages > écriture".
- Le fichier robots.txt :
- soit il est créé réellement sur votre serveur web, et dans ce cas vous n'avez qu'à le modifier pour enlever ou ajouter des règles ;
- Soit il est créé dynamiquement par votre extension SEO (c'est souvent le cas), et il faudra alors trouver le menu correspondant s'il existe pour pouvoir le modifier.
- Le noindex : cette option est souvent gérée par votre extension SEO. Elle peut alors être définie contenu par contenu (par exemple dans la metabox de Yoast SEO) ou de façon globale pour certains types de contenus.
- La redirection 301 ou l'entête 410 : Là encore, c'est souvent une extension SEO qui vous permettra de l'ajouter. Sur WordPress, on peut notamment citer l'extension "Redirection".
- La canonique : nativement, les CMS ont tendance à l'ajouter. WordPress a par exemple nativement des balises canoniques sur certains types de contenu. Ce sont ensuite les extensions SEO qui les améliorent pour s'assurer d'en avoir sur l'ensemble du site. En règle générale, vous n'aurez rien à faire pour que cela fonctionne correctement.
Enfin, pour vérifier un entête HTTP, une balise méta robots, une canonique ou une redirection, nous vous conseillons l'excellente extension navigateur Link Redirect Trace (pour Chrome et Firefox).
Désindexer une URL : le résumé
Résumons maintenant la situation la plus courante : vous avez une URL que vous souhaitez désindexer. Voici ce qu'il faut faire :
1 : Supprimer les liens
Commencez par supprimer tous les liens que vous trouvez vers la page à désindexer
2 : Désindexer une URL
Utilisez la directive noindex. S'il y a des backlinks, du trafic et/ou des mots clés positionnés, optez pour une redirection 301, éventuellement pour une balise canonical.
2bis : Désindexer une ressource
Utilisez un entête 410



Laisser un commentaire