 Parmi les pratiques les plus anciennes en référencement naturel, le fichier robots.txt est toujours utilisé par un grand nombre de référenceur. Mais est-il encore utile ? Et si oui, comment le paramétrer sur votre site Internet et sur WordPress ? Nous allons expliquer ici comme le fichier robots.txt doit être paramétré pour ce CMS.
Parmi les pratiques les plus anciennes en référencement naturel, le fichier robots.txt est toujours utilisé par un grand nombre de référenceur. Mais est-il encore utile ? Et si oui, comment le paramétrer sur votre site Internet et sur WordPress ? Nous allons expliquer ici comme le fichier robots.txt doit être paramétré pour ce CMS.
Dans cet article, nous allons vous expliquer pas à pas comment créer un fichier robots.txt optimisé pour le référencement naturel de WordPress (et en bonus, nous vous donnerons le modèle de robots.txt à télécharger). Et si vous avez besoin d'aide pour l'installer ou l'adapter à votre configuration, faites appel à nos services de développement WordPress.
Qu'est-ce que le fichier robots.txt ?
Le robots.txt est un fichier que l'on place à la racine de son serveur et qui indique aux moteurs de recherches et autres robots le comportement qu'ils doivent adopter quand ils cherchent à indexer votre site Internet. Pour ceux qui ne comprennent pas le terme, "indexer" signifie pour un moteur de recherche d'analyser et de garder en mémoire votre contenu, et donc de pouvoir le proposer dès qu'un Internaute faire une recherche. Le crawl quant à lui est le fait de suivre les liens pour découvrir de nouveaux contenus.
Grâce à ce fichier, vous pouvez indiquer quels contenus doivent être indexés et lesquels doivent être ignorés. Le contenu ne sera donc pas ajouté ou mis à jour dans la base de données de Google (sans pour autant provoquer une désindexation si le contenu était déjà connu de Google). En d'autres termes, c'est une aide pour améliorer votre référencement naturel, notamment pour bloquer l'accès à certains contenus privés, inutiles ou nuisibles.
Le robots.txt ne fait pas tout
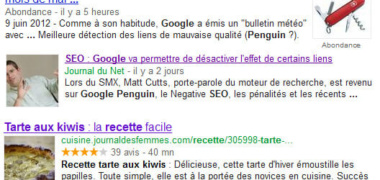
Le hic, c'est que ce fichier est insuffisant pour s'assurer que les pages bloquées ne soient pas visibles dans les moteurs de recherche. La preuve : Google indique dans les résultats que la page n'a pas pu être indexée correctement, mais que celle-ci est quand même présente présent dans son index... En gros, cela veut dire : "on a bien compris votre fichier robots.txt, mais on s'en tape comme de l'an 40" (et tout le monde sait combien c'était fun en l'an 40).

En fait, cela s'explique par le fait que Google a trouvé des liens pointant vers cette page, sans pour autant en connaître le contenu réel puisque vous l'avez bloqué via votre fichier robots.txt. On peut donc se poser la question de la pertinence de Google sur ce point précis.
Si vous utilisez le fichier robots.txt pour restreindre l'accès à certains éléments de votre site Internet, posez-vous donc d'abord ces quelques questions :
- Existe t-il une réelle utilité à restreindre l'accès à ces contenus ?
- Si je restreint l'accès, ai-je limité au maximum les liens qui pointent vers ceux-ci ?
Le fichier robots.txt ne doit jamais être utilisé comme un moyen de cacher certains contenus. Partez du principe que ce que vous devez indexer doit être accessible facilement par l'utilisateur et le moteur de recherche, ce qui repose sur la mise en place d'une structure de site Internet cohérente. Pour être concret : si vous avez un contenu bloqué par le fichier robots.txt, c'est un peu comme si vous aviez une superbe porte d'entrée à l'avant de votre maison, mais que vous disiez aux invités de faire le tour...
Cela ne vous dispense donc pas d'ajouter sur toutes vos pages bloquées une ligne pour lui indique de ne pas indexer le contenu de celles-ci :
<meta name="robots" content="noindex, nofollow">Retenez donc que :
- pour désindexer un contenu déjà présent chez Google, il faut ajouter le <head> le code précédent, et supprimer tous liens qui pointe vers cette page (ou les placer en nofollow) ;
- pour ne pas indexer un contenu non présent chez Google, il faut bloquer l'indexation via le fichier robots.txt, et ne pas faire de liens vers cette page (ou alors uniquement en nofollow.
Robots.txt : fonctionnement de base
Indexer tous vos contenus
Si vous avez dans l'optique de référencer l'intégralité de vos pages, de vos contenus et de vos médias, n'utilisez pas le fichier robots.txt : il ne vous servira à rien.
Par défaut, tous les robots et moteurs de recherche vont indexer tout ce qu'ils trouvent. Donc si vous n'avez rien à bloquer ou à cacher, inutile de lire la suite de cet article et allez plutôt boire un café ou une bière (en fonction de l'heure qu'il est). Attention cependant, je connais peu de sites qui sont dans ce cas de figure...
Bloquer l'accès aux contenus
Le fonctionnement pour bloquer l'accès un contenu grâce au fichier robots.txt est identique sur WordPress que sur n'importe quel autre site Internet. Il faut indiquer le nom du robot concerné suivi des règles que celui-ci devra suivre :
User-agent: Nom du robot
Disallow: répertoire à bloquerDans un même fichier robots.txt, on peut avoir :
- plusieurs user-agent différent.
- plusieurs lignes "Allow" (autoriser) ou "Disallow" (Interdire) pour chaque user-agent.
On peut par exemple bloquer Google sur certains répertoires, Yahoo sur d'autres et Bing sur aucun.
User-agent: Nom-du-1er-robot
Disallow: /repertoire-a-desindexer
Disallow: /2eme-repertoire-a-desindexer
User-agent: Nom-du-2nd-robot
Disallow: /repertoire-a-desindexer
Disallow: /2eme-repertoire-a-desindexer
Disallow: /3eme-repertoire-a-desindexer
...Le fichier robots.txt permet heureusement d'utiliser le caractère * qui indique "quel que soit le contenu" ou "quel que soit le robot". C'est ce qu'on appelle un Wildcard, mais il n'est pas supporté par tous les robots et moteurs de recherche. Heureusement pour nous, les principaux comprennent parfaitement cette commande (Google, Bing, ...). Voici quelques exemples concrets de son utilisation :
User-agent: Nom-du-1er-robot
# tout répertoire qui commence par zigo
Disallow: /zigo*
# toute image au format jpg
Disallow: /*.jpg
# toute URL qui contient le caractère ?
Disallow: /*?
# pour tous les robots
User-agent: *
Disallow: /zigossqdqfSi vous travaillez sur un nouveau site ou que le site est en maintenance, et que vous voulez vous assurer qu'aucun moteur ne puisse rien indexer, il existe une simple commande qui force la non-indexation de tout le contenu par n'importe quel robot :
User-agent: *
Disallow: /Maintenant que vous avez compris le concept de base, voyons comment créer un fichier robots.txt pertinent pour le CMS WordPress.
Un fichier robots.txt pour WordPress
Les fichiers inutiles de WordPress
De base, un nombre relativement important de fichiers issus du cœur de WordPress peuvent être indexés, alors que ceux-ci n'ont aucun intérêt pour le moteur de recherche ou le visiteur. De même, les fichiers de vos plugins ou de vos thèmes ne servent à rien pour l'internaute. Autant indiquer directement dans le fichier robots.txt que vous ne voulez en aucun cas qu'ils soient indexer :
User-agent : *
# On désindexe tous les URL ayant des paramètres (duplication de contenu)
Disallow: /*?
# On désindexe la page de connexion (contenu inutile)
Disallow: /wp-login.phpMAIS, attention à ne pas appliquer ce code. Pourquoi ? Tout simplement car il va vous priver de l'impact positif en SEO de tous les liens provenant d'autres sites et qui contiendraient des paramètres d'URL. Par exemple, si vous faites une opération avec des blogueurs, et que ces derniers ajoutent un tracking aux liens, ceux-ci ne seront pas vraiment pris en compte. Il vaut donc mieux ne pas utiliser la ligne /*?, ce qui donnerait :
User-agent : *
# On désindexe la page de connexion (contenu inutile)
Disallow: /wp-login.phpAvec ce simple code, nous avons déjà une base saine. Mais nous pouvons aller plus loin.
Remarque : je conseillais auparavant de bloquer l'indexation des fichiers des thèmes, de wp-admin et de wp-includes. Désormais Google parvient à exécuter le javascript pour comprendre votre contenu. Il est donc primordial pour le référencement de WordPress de ne plus bloquer l'indexation de ces éléments. Si l'on conserve la fonction Disallow, on va effectivement empêcher l'exécution des scripts de la page, ce qui peut potentiellement nuire à l'indexation de vos contenus. Et sur certains sites, ces scripts sont importants pour pouvoir avoir un réel rendu du contenu.
Référencement et fichiers sensibles
La partie suivante du fichier robots.txt de WordPress permet d'améliorer et de compléter le paramétrage optimale du CMS pour le référencement naturel. Nous allons en effet bloquer l'accès à certains contenus et URL indésirables :
User-agent: *
# On bloque les URL de ping et de trackback
Disallow: */trackback
# On bloque tous les flux RSS sauf celui principal (enlevez /* pour bloquer TOUS les flux)
Disallow: /*/feed
# On bloque toutes les URL de commentaire (flux RSS inclus)
Disallow: /*/commentsAttention, cela ne vous dispense pas de correctement paramétrer votre blog WordPress, sans quoi le code précédent est aussi utile que du pain rassis au beau milieu d'un désert aride. Il vous faut donc :
- Supprimez dans votre thème les liens qui pointent vers les trackbacks de vos articles : c'est une spécificité de WordPress et ce CMS ajoute déjà ces informations dans le header (une section visible uniquement du moteur de recherche). Inutile donc de les garder dans le thème visible par les visiteurs.
- Ne divisez pas en sous-pages vos commentaires, car cela créer des pages souvent pauvres en contenus, tout en diluant inutilement la popularité du site sur des pages secondaires. Pour changer cela, rendez-vous dans l'administration dans "Réglages => Discussions".
- Supprimez dans votre thème toute référence aux flux RSS (sauf celui de l'accueil). Vous pouvez à la rigueur garder ceux des catégories mais par pitié supprimez ceux des commentaires. Dans le cas contraire, je serais obligé de vous abattre à coup de pelle...
Continuons sur notre lancée : certains fichiers ne devraient jamais être accessibles par une autre personne que le webmaster, et encore moins être mis à disposition dans les résultats de recherche de Google, Yahoo ou Bing. Le fichier robots.txt peut heureusement bloquer l'accès à ceux-ci, avec ces quelques lignes :
User-agent: *
# On élimine ce répertoire sensible présent sur certains serveurs
Disallow: /cgi-bin
# On désindexe tous les fichiers qui n'ont pas lieu de l'%C3%AAtre
Disallow: /*.php$
Disallow: /*.inc$
Disallow: /*.gz$
Disallow: /*.cgi$Google Image et Adsense
Vous pouvez aussi choisir de ne pas indexer des pages, mais de faire en sorte que les images qu'elles contiennent soient quand même ajoutées dans le moteur de recherche d'image de Google. Si vous êtes dans ce cas de figure, rajoutez ce code :
User-agent: Googlebot-Image
Disallow:Si comme un grand nombre de sites vous faites appel à la plateforme Adsense pour afficher des publicités, voici quelques lignes qui permettront à leur script de fonctionner parfaitement sur toutes vos pages, quelles que soient les autres lignes de votre fichier robots.txt :
# Autoriser Google AdSense
User-agent: Mediapartners-Google
Disallow:Le sitemap dans le fichier robots.txt ?
Le fichier robots.txt permet aussi d'indiquer l'URL de votre fichier sitemap, qui lui-même recense tous les URL de vos différents contenus, sous la forme suivante :
Sitemap: https://www.monsite.fr/sitemap.xmlHonnêtement, ne le faites pas ! Et la raison en est toute simple : cela ne sert à rien. Il est bien plus efficace d'ajouter votre sitemap directement dans les centres webmaster de chaque moteur de recherche :
- Ici pour Google
- Ici pour Bing et Yahoo
Non seulement c'est plus rapide et efficace, mais chaque centre vous donnera des informations intéressantes sur la validité du fichier sitemap:

Pire encore, si vous indiquez clairement l'URL de votre fichier sitemap, vous facilitez la tâche de tous les personnes qui voudront scanner votre site ou voler vos contenus (il existe des dizaines d'outils gratuits et payants pour cela, croyez-moi...).
Des CSS et JS bloqués par le robots.txt
Depuis quelques temps, il est obligatoire de permettre à Google d'indexer vos contenus correctement, et ceci car le moteur de recherche va en effet visualiser le rendu réel de vos pages. C'est ce que l'on peut notamment voir dans le centre webmaster de Google, dans la section "Exploration > Explorer comme Google". Le moteur de recherche va aussi tester la compatibilité mobile, et pour cela il ne doit pas être bloqué lors de son indexation. C'est pour cela que Google doit impérativement pouvoir accéder aux fichiers JS et CSS.
Si vous êtes dans le cas de figure où vous bloquez les URL avec paramètres (avec /*?), ce que l'on déconsille, il manquera deux lignes à rajouter. Sur WordPress, d'autres CMS ou développements maisons, il est courant d'ajouter à la fin d'un fichier CSS et JS le numéro de version de ce dernier : par exemple style.css?ver=2. L'idée de base est de forcer le téléchargement du fichier lorsqu'on le modifie, par exemple lors d'une refonte d'un thème, de l'ajout d'une fonctionnalité ou de la correction d'un bug. Mais comme nous bloquons les URL avec le paramètre ?, nous bloquerions aussi tous ces fichiers.
Pour éviter cela, on ajoutera donc ces deux dernières lignes dans notre fichier robots.txt pour WordPress :
Allow: /*css?*
Allow: /*js?*Bloquer les paramètres d'URL avec le robots.txt ?
Il est important de bien comprendre l'impact de blocage des URL avec paramètres si vous l'avez mis en place, car cela pose de nombreuses problématiques :
- le site utilise en connaissance de cause des paramètres d'URL à certains endroits ;
- si l'on obtient des backlinks ayant des paramètres dans les URL. Dans ce cas, ces liens pourraient ne pas être pris en compte (on fait un test en ce moment pour vous le confirmer). C'est peut-être le cas des URL suivies par Analytics (par exemple avec des utm_ dans l'URL) ou de services annexes comme Buffer.
Pour résoudre le problème, il existe deux méthodes :
- 1ère solution :
- retirer la ligne Disallow: /*?
- bloquer manuellement chaque paramètre indésirable dans le menu "Exploration > Paramètres d'URL" de la Search Console de Google
- 2nd solution : ajouter des lignes Allow pour chaque type de paramètre d'URL autorisé. Par exemple :
- Allow: /*?utm* (pour Analytics)
- Allow: /*?buffer* (pour Buffer)
- Allow: /*?mon-super-parametre-interne* (pour vos URL internes avec paramètres que vous voulez conserver)
Attention, pour la seconde solution, pour que cela n'ai aucun impact néfaste sur votre référencement naturel et votre indexation, il est impératif que vous ayez mis en place des balises canonical sur l'ensemble de vos contenus, sous peine de negative SEO potentiel par un concurrent qui pourrait générer des centaines d'URL à la volée sur votre site.
Le modèle de fichier robots.txt pour WordPress
Vous l'aurez donc compris (enfin j'espère) : le fichier robots.txt va vous permettre de bloquer l'accès à certains contenus, sans pour autant être la solution miracle. A vous d'optimiser votre site pour bloquer de manière plus complète et naturelle l'accès aux contenus privés, dupliqués ou inintéressants.
Et voici le code final du fichier robots.txt pour WordPress, en utilisant la solution de bloquer les paramètres d'URL :
User-agent: *
Disallow: /wp-login.php
Disallow: */trackback
Disallow: /*/feed
Disallow: /*/comments
Disallow: /cgi-bin
Disallow: /*.php$
Disallow: /*.inc$
Disallow: /*.gz
Disallow: /*.cgi
User-agent: Googlebot-Image
Disallow:
User-agent: Mediapartners-Google
Disallow:Et voici encore plus simplement le lien pour télécharger le modèle de fichier robots.txt.
Attention : c'est un modèle type, qui n'est parfois pas adapté à la façon dont vous avez conçu votre site WordPress !
NoIndex dans le fichier robots.txt
En complément de la directive Disallow, il semblerait que la directive NoIndex fonctionne également pour bloquer le crawl des contenus d'un site ou de WordPress (source : Disallow et NoIndex). On pourrait donc, au lieu de bloquer l'accès à certains contenus, permettre la désindexation via cette commande, ce qui donnerait :
User-agent: *
Noindex: /*?
Noindex: /wp-login.php
Noindex: */trackback
Noindex: /*/feed
Noindex: /*/comments
Noindex: /cgi-bin
Noindex: /*.php$
Noindex: /*.inc$
Noindex: /*.gz
Noindex: /*.cgiAttention cependant, bien que le moteur de recherche Google semble la prendre en compte, rien d'officiel n'a jamais été publié. Je conseille donc d'être prudent. De plus, le moteur de recherche ne prendra en compte que les premières directives. Vous devez donc choisir entre :
- Noindex : le robot peut suivre les URL mais ne pas indexer le contenu ;
- Disallow : le robot ne suivra pas les URL.
Par sécurité, préférez toujours la version habituelle en Disallow donnée plus tôt dans cet article.
Si vous avez des remarques, questions ou critiques, n'hésitez pas.



72 Commentaires
Juste une remarque : les SWF sont aujourd'hui indexés par Google !
Merci pour cet excellent travail, Daniel !
Concernant le sitemap, je ne suis pas d’accord eu égard au nombre de spiders qui l’indexent « spontanément » ! De mon point de vue, c’est une erreur.
N’oublions pas Yandex.
Merci pour cet article.
Petite précision : Google n'ignore JAMAIS le roboots.txt
- Avec le robots.txt, tu dis à Google de ne pas crawler tel ou tel contenu, et jusqu'à preuve du contraire c'est systématiquement respecté (et ce sera une révolution le jour ou ça changera).
- Par contre, tu ne lui interdit pas d'indexer, et dans certains cas il peut indexer du contenu sans l'avoir crawlé (mais peu probable d'espérer beaucoup de trafic dans ce cas...).
- Si tu veux interdire l'indexation, il faut utiliser un no-index. La subtilité étant que si la page est bloquée dans le robots.txt, Google ne peut pas voir qu'il y a un noindex...
Bonjour !
Il est vrai que le problème illustré par le screen de search enfine land se rencontre assez souvent.
Autre bug rencontré parfois avec WordPress : dans vie privée, l'option "ne pas indexer" est cochée dans un premier temps et lorsqu'on veut mettre le site en ligne et qu'on coche l'option "indexer mon site", cela ne change rien.
Dans ce cas le fichier robots peut être d'un grand secours.
Ce n'est pas forcément une bonne idée de bloquer la totalité des JS à Google.
On sait tous que Google s'en sert pour interpréter les pages. Parfois jquery est nécessaire pour des onglets, pour des actions permettant de masquer/afficher du contenu, etc. Il faut que GG puisse "comprendre" que ton div caché peut être affiché par une action utilisateur.
Pour ma part je bloque les JS indirectement : je disallow un répertoire complet dans lequel je mets les JS que je ne veux pas montrer (cryptage / obfuscation notamment).
Autre oubli
Concernant les fichiers js et css, Matt Cutts avait recommandé de ne pas les désindexer !
A la vue de mes logs Apache, les bots de Baïdu, d'Exalead, ... utilisent les indications fournies par le fichier robots.txt sur l'emplacement du fichier sitemap ! Il est donc indispensable de maintenir ce fichier et l'information sur son emplacement.
Quelle prise de tête ce robots.txt! Récemment j'ai eu le cas, un robots.txt (made in seomix) ignoré tranquillement.. le fichier lui même était indexé.
Aujourd'hui, je l'ai carrément supprimé
bon article, par contre vous ne parlez pas du fichier robots.txt virtuel qui est généré par WordPress.
c'est un fichier basique qui ne comporte que ces 3 lignes :
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
d'après ce que j'ai compris ce fichier est généré par WordPress quand il n'y a pas d'autres fichiers robots.txt, mais il n'est pas présent "physiquement" sur le serveur, par contre contre si on tape https://www.monsite.com/robots.txt alors on le voit.
En ce qui concerne le sitemap.xml.
Ok c'est sûrement mieux d'utiliser les outils de webmasters proposés par Google et Bing.
Mais si on ne le met pas, comment vont faire les moteurs de recherche autre que Google et Bing ?
De plus, le sitemap est souvent (je pense) à la racine du site, les outils de pompage de site ne sont pas stupide, qu'il soit indiqué ou non dans le robots.txt, j'imagine qu'ils iront guetter à l'aveuglette le monsite.fr/sitemap.xml, non ?
Sinon, dans votre article vous parlez de bloquer les commentaires et les flux rss, pourquoi ces lignes ne sont pas dans le fichier robot final ?
Elles sont inutiles ou c'est un oublie ?
En tout cas merci pour cette article détaillé.
@Denis: remarque pertinente pour le fichiers SWF, c'est corrigé.
A ceux qui ne sont pas en accord avec ce que je dis sur le sitemap dans le fichier robots.txt, il faut savoir que seuls les robots qui apporteur du trafic sont pertinents, à savoir Google en France (éventuellement Bing et Yahoo, mais c'est tout). Mieux vaut une belle page plan de site complet, une structure cohérente et un bon maillage interne pour assurer l'indexation de n'importe quel contenu. L'ajoute au robots.txt ne facilitera pas la tâche de Google et Yahoo. D'ailleurs, rien n'empêche de nommer son fichier sitemap toto.xml et de le soumettre comme tel dans les centres webmaster.
@Watussi : Google ignore parfois le robots.txt malheureusement. La preuve avec l'image dans cet article et avec plusieurs tests de référenceurs sur le sujet.
@François-Olivier: d'accord aussi avec toi pour les fichiers JS. C'est corrigé.
@Denis: pour le CSS, c'est corrigé aussi.
@Jimmy : mieux vaut passer outre le robots.txt virtuel de WordPress. Il est malheureusement incomplet...
@Benone : pour les flux dans le code final, c'était un simple oubli.
Merci pour ces différents éléments plutôt pertinents ;)
Comme certains commentaires précédents, j'attirerais l'attention sur le fait qu'il n'y a pas de règles globales à appliquer à tout site WP mais bien des grands principes qu'il faut parfois ajuster au cas par cas.
Par exemple, le Disallow: /*? c'est très bien ... à condition de bien avoir activé la réécriture d'URL ! et aussi de ne pas avoir de plugins (anciens ou mal codés) créant des URLs avec paramètres pour du contenu pertinent.
De plus, ne pas oublier que ce fichier est aussi un "trou" de sécurité au sens où vous indiquez aux pirates potentiels où trouver les fichiers "sensibles".
Par exemple, il n'est pas rare de sécuriser l'accès au Back Office de WordPress en modifiant son URL (/wp-admin et wp-login par défaut). Dans ce cas, il ne faut bien entendu pas mettre ces nouvelles URLs dans le robot.txt car il est bien entendu accessible par tous !
@Daniel,
Je pense que tu as mal lu / compris mon commentaire.
Ce qu'il faut bien comprendre c'est que le robots.txt ne sert pas à interdire l'indexation, mais à interdire le crawl. Généralement l'un va de pair avec l'autre, mais pas toujours.
L'image de ton article prouve que la page a été indexée, rien d'autre.
Jusqu'à preuve du contraire, Google ne crawl pas les URLs interdites via le robots.txt
Cette nuance est très importante à comprendre.
C'est d'ailleurs bien documenté par Google : https://support.google.com/webmasters/bin/answer.py?hl=fr&answer=156449
@Watussi : j'avais bien compris. Mais j'ai déjà eu le cas de pages interdites dès leur création et qui ont été quand même crawlées et indexées... Le robots.txt n'est donc la solution parfaite et complète pour bloquer un crawl de robots, et encore plus si ces robots viennent aspirer le contenu d'un site.
Je me pose une question :
En mettant des Disallow: dans le robots.txt ont dit aux bots de ne pas indexer.
Il comprend donc que tout ce qui a pas Disallow, il peut l'indexer ?
Du coup, est-ce que les Allow: servent à qqch ?
@Daniel
Pour l'intitulé du fichier sitemap, je reprenais là une convention, un usage. Il ne me viendrait pas à l'idée de l'appeler toto.xml ! ;+)
Pour mes sites WordPress, j'utilise d'ailleurs le plugin Google XML Sitemaps. Excellent !
@Daniel Merci pour cet excellent article. Tu m'as promis un article sur le nettoyage des sites WordPress hackés, n'oublies pas hein! :p
@Watussi @François-Olivier et @visiboost pour les commentaires tout aussi intéressants.
Salut Daniel
quand tu dis : " Google indique désormais dans les résultats que la page n'a pas pu être indexée correctement, mais que celle-ci est quand même présente présent dans l'index..."
=> Ce n'est pas vraiment ça : Google indique ainsi qu'il connait l'uRL de la page, il sait qu'elle existe mais il ne l'a pas indexé. Il n'a pas connaissance de son code. Ca a toujours été comme ça, sauf qu'avant il mettait en titre l'URL de la page et aucun snippet. Maintenant, il met ce message... Donc le robots.txt sert bien à quelque chose :-)
Idem : " Honnêtement, ne le faites pas ! Et la raison en est toute simple : cela ne sert à rien. Il est bien plus efficace d'ajouter votre sitemap directement dans les centres webmaster de chaque moteur de recherche"
=> Ca sert quand meme pour voila, ask.com, Exalead et tous les autres moteurs qui prennent en compte le standard Sitemaps.org et n'ont pas de webmaster tools. Bon ok c'est pas les principaux mais bon... :-))
Bonne continuation. a+
@Benone : par défaut, les robots font ce qu'ils veulent. Le "allow" ne sert que pour contre-carrer une commande "disallow", comme dans cet article où le "allow" autorise le répertoire "uploads" situé dans le répertoire "wp-content", qui lui est bloqué.
@Olivier : pour le premier point, c'est un peu complexe car théoriquement, Google n'a pas suivi le lien et n'a pas indexé ni "lu" le contenu. Si c'est vrai, alors pourquoi la page ressort dans les résultats alors qu'il n'en connait rien, pas même le title... En d'autres termes, il a quand même pris connaissance de son contenu (ou alors Google est devin...).
Je suis tout à fait d'accord sur le second point. Mais pour ma part, je préfère freiner les autres robots car le potentiel de trafic ou de ROI possible est bien inférieur aux risques de vol de contenu, de consommation de bande passante énorme et autres joyeusetés...
@ Daniel : "Si c’est vrai, alors pourquoi la page ressort dans les résultats alors qu’il n’en connait rien, pas même le title"
C'est simple : il a identifié un lien vers cette page, donc il la connait. :-)
C'est aussi ce que je me suis dit, mais dans ce cas cela va à l'encontre total des "conseils" donnés par Google sur le "Content is King". Il serait aberrant de positionner une URL sans même en connaître le contenu...
Les lois, c'est Google qui les fait mais rien ne dit qu'il doit les appliquer à lui-même :-)))
Olivier a raison, c'est ce que j'essayais d'expliquer plus tôt dans la journée.
Généralement, lorsqu'une page interdite dans le robots.txt ressort dans les SERPs, tu vois que le TITLE n'est pas le TITLE réel, c'est souvent une ancre de lien découverte par ailleurs qui est utilisée.
En gros si Google ne peux pas rentrer dans un appartement par la porte principale qui est fermée à clé, il va passer par le balcon du voisin qui fait fasse à la fenêtre restée ouverte.?
@BenOne : Allow: n'a jamais été admis dans le standard et ne veut d'ailleurs rien dire. C'est un simple fichier texte donc une info erronée ne renvoie pas d'erreur.
Je crois que seul Google a dit qu'il comprenait le Allow: mais qui, encore une fois, ne sert à rien puisque tout ce qui n'est pas Disallow est autorisé.
@Olivier
La soumission du sitemap à Ask ne fonctionne plus depuis quelques temps. Je ne sais pas dater précisément. J'avais lâché l'affaire.
Et l'indexation des sites semble se faire très, très bizarrement !
@François-Olivier
Allow gère les exceptions à l'interdiction.
Disallow: /wp-content
Allow: /wp-content/uploads
=> interdire l'accès au répertoire /wp-content/ sauf le sous répertoire /uploads/
Donc si je comprends bien les commentaires, Google sait qu'il y a une page parce qu'il y a un lien qui pointe vers elle mais ne l'indexe pas car il ne la lit pas a cause du robots.txt ?
Mais il l'indexe quand même ...
Sincèrement, j'ai commencé à lire l'article en me disant : "je maitrise pas mal la gestion du robots.txt, je risque de pas y apprendre grand chose". Finalement, de très bon conseils, et contrairement à ce que je pensais, j'ai appris quelques trucs bien utiles que je me suis empressé d'appliquer sur mon site.
Merci !!
Merci pour ces précisions sur le robots.txt, même si on peut se poser réellement la question de l’intérêt de ce fichier...
Concernant le sitemap, il y a 2 écoles :
- créer ce fameux fichier et le proposer au moteur pour bénéficier d'une indexation rapide quelque soit la structure du site.
- ne pas générer de sitemap et attendre l'indexation de son site par les moteurs et ainsi valider la structure technique du site (puisque les moteurs ont réussi l'indexation).
Hello Daniel
Merci pour tes éclaircissements
Comme le fichier Sitemap est souvent aussi en .gz, je ne voie plus l'intéret de cette ligne
Disallow: /*.gz
David
Bonjour Daniel,
Merci beaucoup pour ton article. J'ai une installation WordPress et Google vient de me faire remarquer aujourd'hui qu'il ne trouve pas mon fichier robots.txt à la racine de mon nom de domaine. Et effectivement, il n'y en a pas, il n'y en a jamais eu d'ailleurs. Mais le fichier sitemap est bien présent lui (dans un sous répertoire "nomdedomaine.fr/blog").
J'en conclus qu'il faut que je rajouter le fichier robots.txt à la racine de mon site, est-ce bien cela ta recommandation ?
Par ailleurs, j'ai la structure suivante :
nomdedomaine.fr/blog
nomdedomaine.fr/forum
En quoi cela modifie-t-il le modèle du fichier robots.txt que tu proposais en fin de ton article ?
Merci beaucoup pour ton éclairage.
@Cédric : pour le blog, cela ne change rien. Par contre il faudra tester avec le forum pour voir s'il n'y a pas d'incompatibilité.
Bonjour,
Est-ce que "Disallow: /*?" signifie que les pages du moteur de recherche avancé sur mon site ne seront pas visibles par Google ?
Merci de m'éclairer à ce sujet parce qu'il me remonte plein d'erreurs 404 dans Google Webmaster Tool (uniquement des urls du moteur de recherche) :(
Bonne journée !
Cela signifiera que cela bloquera toutes les URL qui utilisent un ?, que ce soit votre moteur de recherche interne ou un autre type d'URL.
Merci beaucoup pour votre explication !
Quelque chose de simple, mais tout de même à mentionner :
le robots.txt décrit sera inefficace si les fichiers de WordPress se situent dans un sous-dossier, et c'est souvent le cas.
Il faut donc rajouter /nomdudossier devant chaque adresse sur chaque ligne si les fichiers wordpress ne sont pas directement à la racine du site.
Salut
Je suis assez perplexe sur l'utilisation du " Disallow: /*? "
Avec cela, tu indiques à Google : "merci de ne passer sur aucune des pages avec un paramètre dans l'url"
Bref, n'importe quelle url avec un paramètre de tracking qui se retrouverait dans un forum par exemple ne serait donc pas interprété et aucun PageRank passé... C'est dommage, d'autant plus qu'il n'y aucun risque de duplicate, en particulier si les canonical sont bien gérés.
Bref, personnellement, je déconseille nettement l'utilisation cette ligne.
De manière générale, j'utilise le robots.txt en dernier recours après avoir bien géré les noindex et les canonical... Et, au final, parfois, je n'ai rien à mettre dedans si ce n'est le sitemap ;)
Perso, j'utilise aussi le /*?
Pour tout te dire, voici mon robots.txt de base pour WordPress que j'utilise presque tout le temps :
Bonjour Sébastien,
Cela permet d'économiser (un peu) de crawl allocation, et pour les gros sites, c'est intéressant.
Bonjour Daniel,
Si j'ai bien compris la problématique soulevée par le commentaire de Sébastien, il faudrait que Google puisse crawler les URL avec paramètre pour laisser passer le jus, mais ne les indexe pas pour éviter le DC, c'est bien ça ?
Si oui, je tente une réponse mais c'est à tester. La parade serait d'utiliser "Noindex: /*?" dans le robots-txt, au lieu du disallow habituel.
La commande n'est apparemment pas documentée par Google, mais tu trouveras une longue démonstration sur le site WRI; ladite commande fait l'objet de la conclusion de l'article.
https://www.webrankinfo.com/dossiers/indexation/crawl-respect-robots-txt
Bonjour,
Question bête : dans le cas d'un blog (monsite.fr/blog), il faut procéder de la même façon ou faire par exemple : Disallow: /blog/wp-login.php ?
Merci !
Effectivement, le mieux est de rajouter /blog/ devant chaque ligne
Daniel (vous n'êtes pas par hasard le frère de Jean ? ;)
Tout d'abord, merci, merci pour votre blog !
J'apprécie particulièrement votre façon de présenter, comme par ex. l'article ci-dessus, façon genèse.
Avoir les connaissances dans un domaine c'est une chose, savoir les transmettre c'est tout un art,
Et vous le faites très bien !
Merci encore
Bonsoir,
Je un souci avec mon fichier robots.txt.Je suis inscrit au service de référencement de Attracta et ils ont inséré trois lignes dans mon fichier robots qui commence par:
#Begin Attracta SEO Tools Sitemap.
et se termine par:
#End Attracta SEO Tools Sitemap. Do not remove
Le problème c'est que ce fichier robots n'est pas reocnnu dans Google webmaster tools. Or, je voudrais utiliser votre code. Mais même en l'insérant dans ce fichier robots.txt, il ne sera toujours pas compatible.
Avez un suggestion à me proposer?
Merci.
Le mieux est de demander directement à Attracta pourquoi votre le robots.txt de votre WordPress n'est pas reconnu comme compatible.
Salut Daniel,
Le tuto est t'il encore d'actualité stp?
Damien
Oui, il l'est toujours.
Bonjour Daniel,
Question concernant les "category" de WordPress, faut-il les désindexer car on peut en effet considérer que ces pages créent une sorte de "duplicate content" des articles contenus dans chacune des catégorie ?? Est-il donc nécessaire d'ajouter ces lignes dans le fichier robots.txt :
Disallow: /category/
Noindex: /category/
Les catégories permettent justement aux visiteurs et moteurs de recherche de trouver vos contenus. Il ne faut donc pas les désindexer, mais il faut s'assurer qu'elles n'affichent qu'un extrait des articles et pas la totalité.
Bonjour,
Dans les réglages généraux de WordPress, mon "Adresse web de WordPress" (https://www.monsite.ch/wordpress) est différente de mon "Adresse web du site" (https://www.monsite.ch).
Est-ce que dans le fichier robots.txt je dois donc insérer partout "/wordpress", soit par exemple "Disallow: /wordpress/wp-login.php" au lieu de "Disallow: /wp-login.php" ?
Merci pour votre aide!
Claude
PS: votre bouquin sur le référencement est une vraie perle, merci :-)
Pour tout ce qui commence par wp-, il faudra en effet rajouter /wordpress/ juste avant
Bonjour, et merci pour l'article,
J'ai mis votre fichier robot mais j'ai un problème, quand je tape mon site sur google, en dessous il me met: "La description de ce résultat n'est pas accessible à cause du fichier robots.txt de ce site. En savoir plus " Quel est le problème ?
Cela indique que certaines pages du site sont bloquées par le robots.txt. Celui donné ici est un fichier type, mais il faut peut-être l'adapté en fonction de vos besoins et des spécificités de votre site.
Hello Daniel,
J'ai remarqué sur mon site que la ligne Disallow: /*? empêchait de passer le test mobile friendly alors que le site est mobile responsive...Tu as déjà vu ça ?
En ajoutant les deux dernières lignes, je n'ai jamais eu ce soucis.
Avec, les fichiers "css" et "js" c'est ok. J'avais pris ton ancien code.
Bonjour Daniel,
malgré les instructions dans le robots.txt, je vois toujours les URLS dans Xenu, c'est normal ?
Par exemple j'ai demandé à desindexer les URLS contenant ? ou encore /feed et toujours là visiblement :-/
J'ai réessayé de modifier le fichier, on verra dans quelques jours si ça change quelque chose.
Merci,
A+
Xenu ne prend pas en compte le fichier robots.txt : il scanne tout le site. Pour faire un crawl "traditionnel", utilisez plutôt Screaming Frog Spider SEO.
Merci pour l'update. Testé et approuvé
Bonjour Daniel,
Existe t-il un moyen de protéger son site du vol de contenu via le fichier Robot txt ? Si oui, lequel ? Merci d'avance.
Malheureusement non : le robots empêche les robots de passer, mais pas ceux des voleurs de contenus (et encore moins de leurs actions manuelles)
Merci pour ta réponse. Si je te comprends bien, il n'y a pas de solution.... Peut-être faut-il carrément supprimer son sitemap ? A part obtenir des liens et bosser sur le maillage interne, il n'y a pas de solution à t'entendre...
Malheureusement oui (et supprimer le sitemap ne changera rien)
Bonjour,
Y a t-il une différence importante entre le code que vous donnez sans le point :
[code]
Allow: /*css?*
Allow: /*js?*
[/code]
et celui-ci avec le point:
[code]
Allow: /*.css?*
Allow: /*.js?*
[/code]
merci
Pas vraiment de différence ;)
Bonjour,
Tout d'abord merci pour cet article. J'ai reçu récemment un mail de google se plaignant de ne pas avoir accès aux fichiers JS et CSS. J'ai modifié mon fichier robots.txt qui est devenu:
User-agent: *Disallow: /*?
Disallow: /wp-login.php
Disallow: /wp-login.php?
Disallow: */trackback
Disallow: /*/feed
Disallow: /*/comments
Disallow: /cgi-bin
Disallow: /*.php$
Disallow: /*.inc$
Disallow: /*.gz
Disallow: /*.cgi
Allow: /*css?*
Allow: /*js?*
Allow: /*.css?*
Allow: /*.js?*
User-agent: Mediapartners-Google
Disallow:
Aurais-je un problème ?
Normalement non, mais après il faut parfois adapter le code au site : il faudra donc surveiller les différents menus du cente webmaster
Je vous remercie de votre réponse. Votre site est une mine d'information pour l'optimisation des sites sous WordPress. Bonne continuation.
Bien cordialement
Bonjour, merci pour votre article.
Combien de temps le fichier TXT est pris en compte par google parce que mon fichier Txt est toujours le même de base après l'avoir modifié, est ce que google l'a bien pris en compte ?
Merci d'avance.
Pour savoir si Google a bien pris en compte votre fichier robots.txt, il faut simplement se connecter à votre compte Google Search Console.
Merci pour l'article. J'arrive un peu tardivement...
Y-a-t-il un moyen d'empécher GG d'indexer les pages du cache tout en lui en autorisant la lecture. J'utilise wp rocket et la quantité de css, js présente dans le cache et indexée par google est impressionnante (constaté avec l'extension redirection).
Que Google les indexe n'est pas gênant en soit, en revanche cela génère une quantité énorme de 404 lorsqu'il revient les crawler. Cela ralentit probablement mon site (je me bats actuellement pour comprendre les raisons des temps de réponse en dent de scie dans GSC).
J'ai bien pensé à interdire l'indexation du cache, mais en testant la page dans GSC GG m'indique que sont robot a été bloqué et qu'il n'a pas pu charger les ressources. Il m'indique évidemment le path du cache que j'ai interdit dans le robot.txt
Sur SeoMix, nous renvoyons un code 410 lorsqu'une 404 est générée sur une URL de cache : GoogleBot repasse bien moins souvent depuis sur ce type d'URL
Article très utile ! Vous expliquez clairement à quoi sert le fichier robots.txt dans WordPress et comment le configurer correctement — un guide pratique pour sécuriser et optimiser son site. Merci pour ce partage !
Laisser un commentaire